RprobitB implements Bayes estimation of probit choice models in cross-sectional and panel settings. The package can analyze binary, multivariate, ordered, and ranked choices, as well as heterogeneity of choice behavior among deciders. The main functionality includes model fitting via Gibbs sampling, tools for convergence diagnostic, choice data simulation, in-sample and out-of-sample choice prediction, and model selection using information criteria and Bayes factors. The latent class model extension facilitates preference-based decider classification, where the number of latent classes can be inferred via the Dirichlet process or a weight-based updating heuristic. This allows for flexible modeling of choice behavior without the need to impose structural constraints. See the vignette on the model definition for details about the probit model.
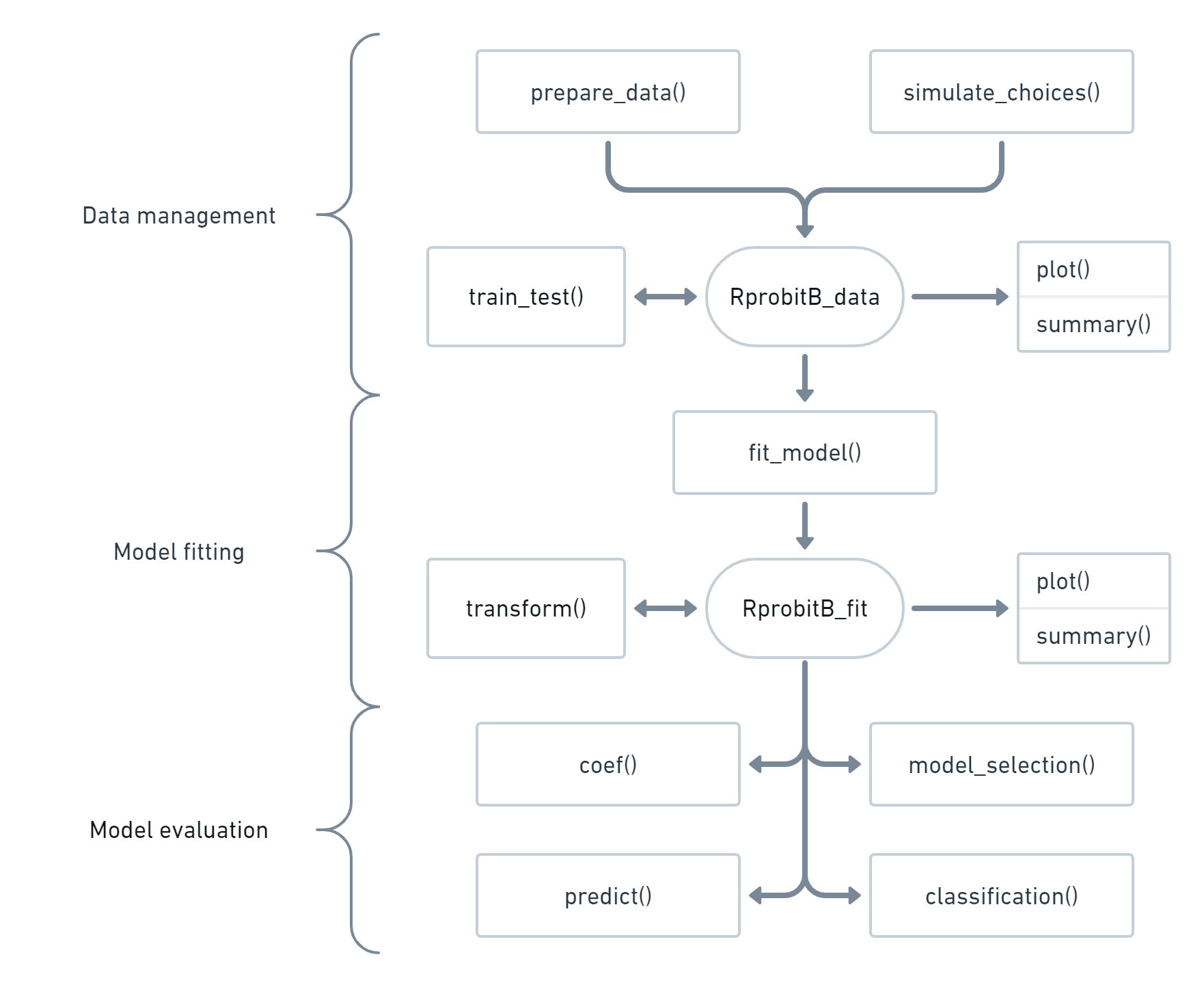
Working with RprobitB follows a structured workflow. The main functions fall into three categories: data management, model fitting, and model evaluation, as illustrated in the flowchart below. A typical workflow proceeds as follows:
Prepare a choice data set via the
prepare_data()function or simulate data viasimulate_choices(). Both functions return anRprobitB_dataobject that can be fed into the estimation routine. Thetrain_test()allows to split the data into an estimation and a validation part. See the vignette on choice data for details.The estimation routine is called
fit_model()and returns anRprobitB_fitobject. Thetransform_fit()function allows to change normalization of the model after a model has been fitted. The details are documented in the vignettes on model fitting and on modeling heterogeneity.The
RprobitB_fitobject can be fed intocoef()to show the covariate effects on the choices and intopredict()to compute choice probabilities and forecast choice behavior if choice characteristics would change, see the vignette on choice prediction. Theclassification()function allows for preference-based decider classification. The functionmodel_selection()comparesRprobitB_fitobjects by computing different model selection criteria, see the vignette on model selection.